Ora viva,
Eu recentemente tenho tido vários problemas com as internets da NOS à noite, e isso tem me feito andar a fazer diversos telefonemas a reclamar e a ser sempre obrigado a correr o speedtester deles.
Até há poucos dias era uma cena normal.js que funcionava na maioria dos browsers, e uma applet JEWVA para o IE com extra faggotry. Mas agora decidiram INOVAR, e quando se inicia o teste, força o download de um .exe que supostamente tens que correr para fazer o speedtest, se não tiveres Windoze, azarito, não tens direito a te queixares com problemas de internets.
Bem, um .exe vindo da NOS não me parece uma boa ideia, então primeiro decidi enviar o executável para o virustotal para fazer scans, e o resultado foi:

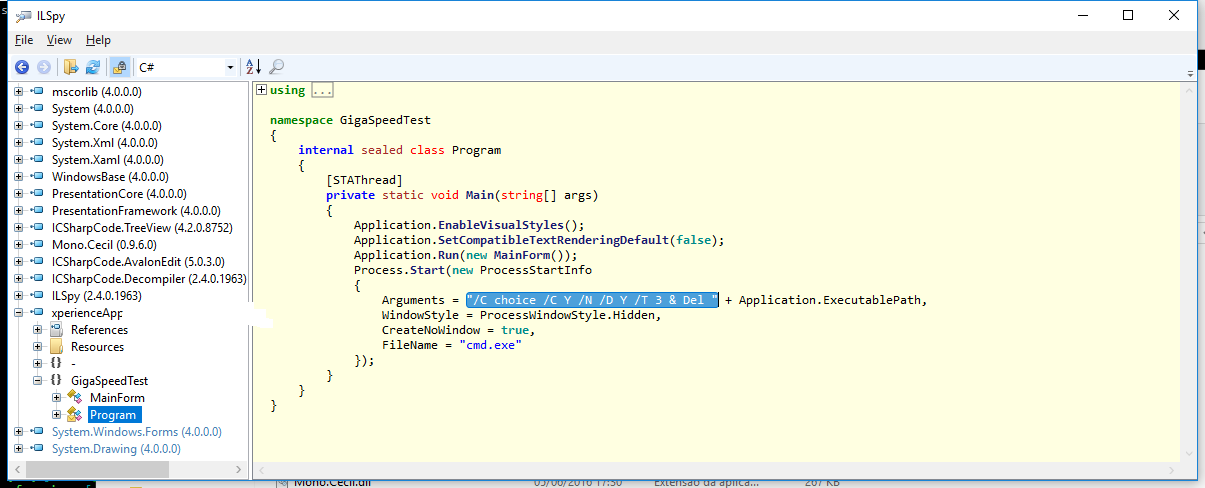
Achei estranho como é normal, e ainda mais estranho eles não terem visto isto antes. Bora la então tentar ver o que isto faz. Vi que o executável era .NET portanto fui procurar um .NET decompiler, usei o ILSpy e vi o seguinte:
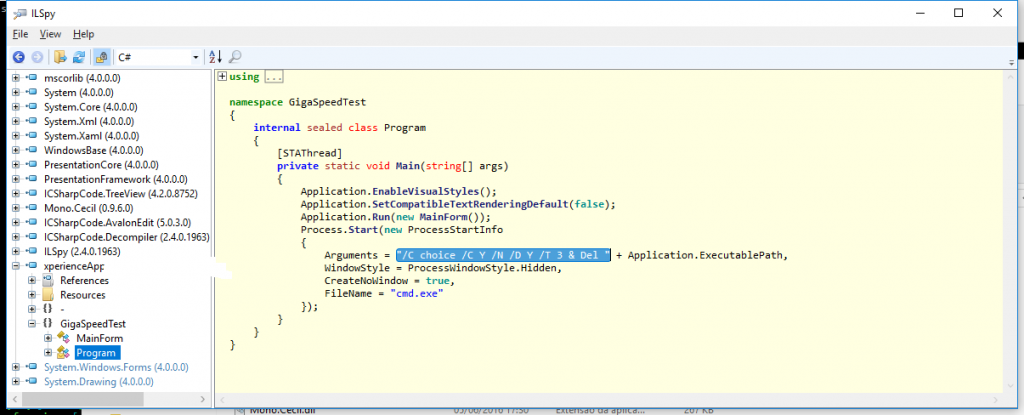
Achei que aquela string era um argumento para qualquer coisa Windoze based devido aos /qqcoisa, então googlando pela string achei este artigo, que explica que isto é usado para correr uma aplicação e apaga-la quando ela termina.
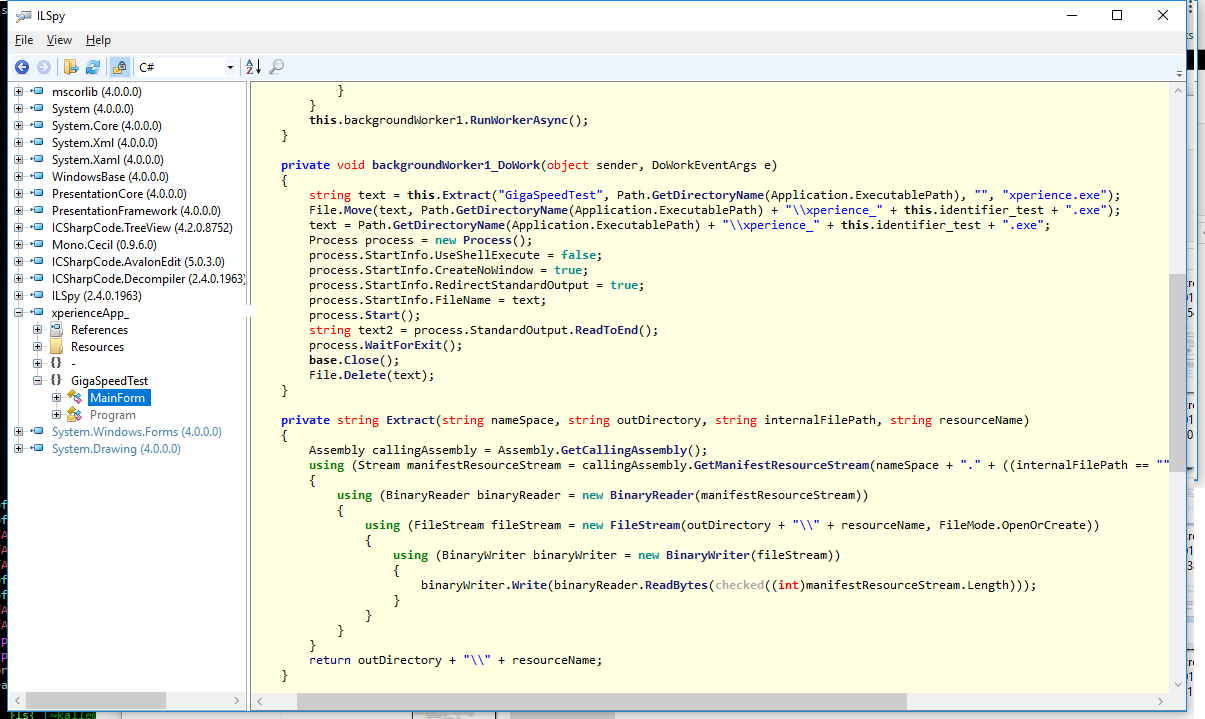
Passando para o MainForm, vi o seguinte:
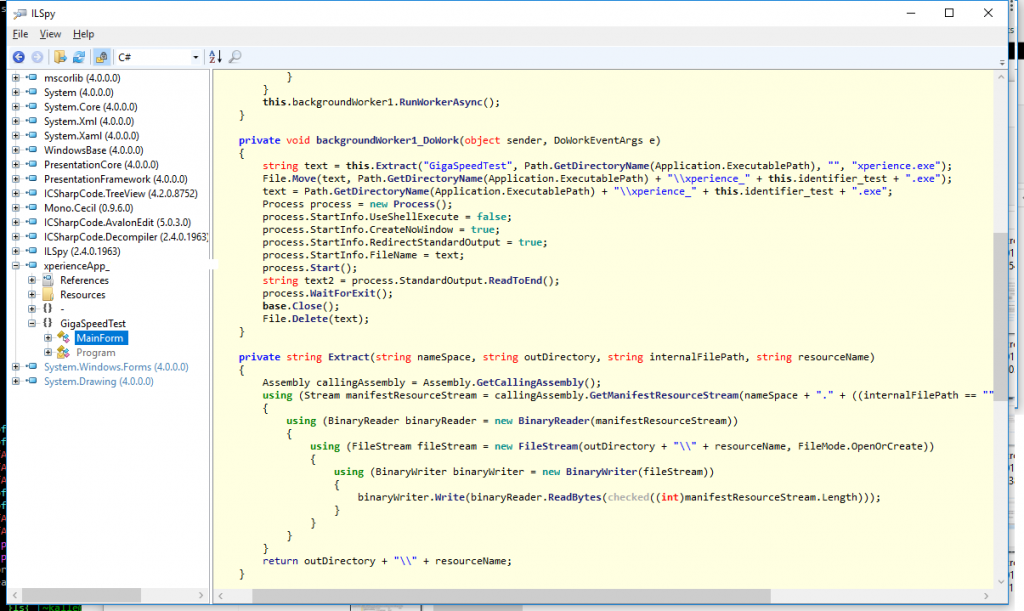
Que mostra que tem outro executável embutido nele, extrai-o e executa, reparei também que no site da NOS, cada utilizador que faz download do speedtest, o ficheiro tem um nome diferente, chama-se "xperienceApp_XXXXXXXXXXXXXXXXXXXXX.exe" sendo o X diferente para cada utilizador ou cada IP da NOS que faz download do ficheiro, ainda não entendi bem isso, mas pelo que entendi esse ID é que depois é utilizado quando se faz o upload do resultado dos testes, portanto deve ser possível aldrabar isto :-P
Fui então tentar sacar os executaveis embutidos, e lembrei-me logo do binwalk, o resultado é o seguinte:
DECIMAL HEXADECIMAL DESCRIPTION
--------------------------------------------------------------------------------
0 0x0 Microsoft executable, portable (PE)
...
507768 0x7BF78 Microsoft executable, portable (PE)
...
887308 0xD8A0C Microsoft executable, portable (PE)
...
Mandei um binwalk -D 'microsoft:exe' xperienceApp_XXX.exe e passei ter mais dois executáveis gulosos. Então siga aprender a usar o radare2 só para dar numa de elite!
O primeiro executável, nas strings tem referencias ao curl, portanto faz requests para algum lado :-)
Depois fui cuscar o main, como vi antes, parece ir buscar um id, que pelos vistos é um ticket number ao NOME do executável, não ponho o dissassembly todo porque são mil linhas:
push str.xperienceApp ; 0x457728 ; "xperienceApp"
...
push 0x457738 ; "_"
...
push 0x457740 ; ".exe"
...
push 0x456c68 ; "_"
...
push str.Ticket_Number:__s_n ; 0x456c6c ; "Ticket Number: %s\n"
...
push str.Wrong_Application_Name__Please_download_the_application_again__n ; 0x456c80 ; "Wrong Application Name (Please download the application again)\n"
Mais para baixo também tem umas strings gulosas:
push 0x456e50 ; "Kanguru.exe"
...
push 0x456e5c ; "UIMain.exe"
...
push 0x456e68 ; "Optimus Kanguru.exe"
...
push 0x456e7c ; "MphoneTools.exe"
...
push 0x456e8c ; "AT+CIMI\r"
...
push 0x456edc ; "AT+CGSN\r"
...
push str.IMEI ; 0x456e98 ; "IMEI"
...
push str.Exception_when_try_to_open_COM_Port_n ; 0x456ee8 ; "Exception when try to open COM Port\n"
Diria que estão a procurar se esses executáveis estão a correr, que são clientes de modems 3G, e a ligar-se ao modem, a sacar a rede a que está ligada, o serial number e o IMEI, vai-se la entender porque é que o speedtest precisa disto tudo :-)
Mais para baixo, faz downloads em modo sequencial e paralelo via curl, e envia os dados para um servidor, por HTTP, porque HTTPS é coisa do futuro. E não tem mais nada.
Seguindo para o próximo, cuscando as strings, também usa o curl, porque raio é preciso outro programa?
string=\pcdiag_tempFile.txt
string=wmic os get freephysicalmemory
string=%s > %s%s
string=wmic os get caption
string= nicconfig where IPEnabled=True get Caption /format:table
string=netsh wlan show interfaces
string= PROCESS get name / Format:table
string=wmic /output:%s%s %s
string=netsh advfirewall show allprofiles state
string=wmic NIC where NetEnabled=true get Name, Speed | find "%s"
string=results_content: %s \n
string=PC Results Sended\n
(SENDED LOL)
Pelo que vi no dissassembly deste, tem as mesmas funcionalidades do anterior, mas tem uma parte EXTRA chamada "PC_Diagnostic" que cria um ficheiro temporário, e corre uma carrada de comandos do Windoze, manda o output para la, e provavelmente depois envia esse ficheiro para o servidor deles, novamente por http.
* Vê a lista dos processos que estão a correr;
* Corre o wmic para obter montes de informações do PC e dos interfaces de rede;
* Apaga a KEY "ProxyBypass" no registry em HKCU\SOFTWARE\MICROSOFT\WINDOWS\CURRENTVERSION\INTERNET SETTINGS\ZONEMAP e em "HKLM\SOFTWARE\MICROSOFT\WINDOWS\CURRENTVERSION\INTERNET SETTINGS\ZONEMAP";
* Le o "HKLM\SOFTWARE\MICROSOFT\WINDOWS\CURRENTVERSION\APP PATHS\CMD.EXE" que contem uma lista de apps instaladas;
Bem, para poder reclamar sem correr esta sida no meu PC, decidi sacar uma VM com o Windoze, e testar isto lá.
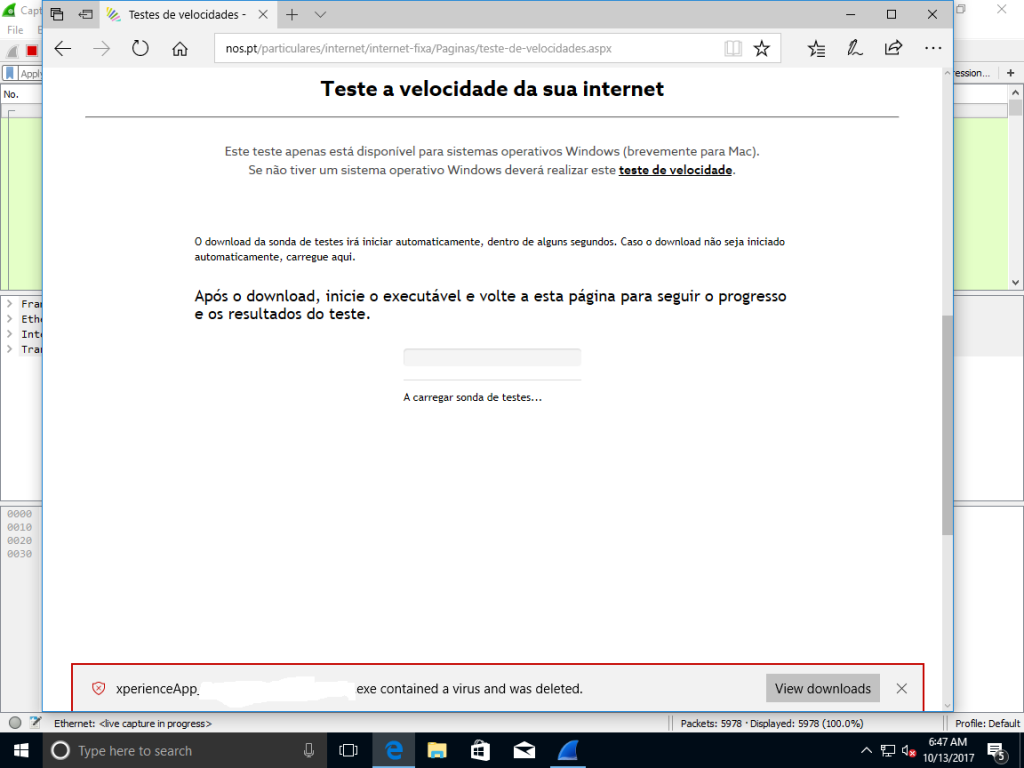
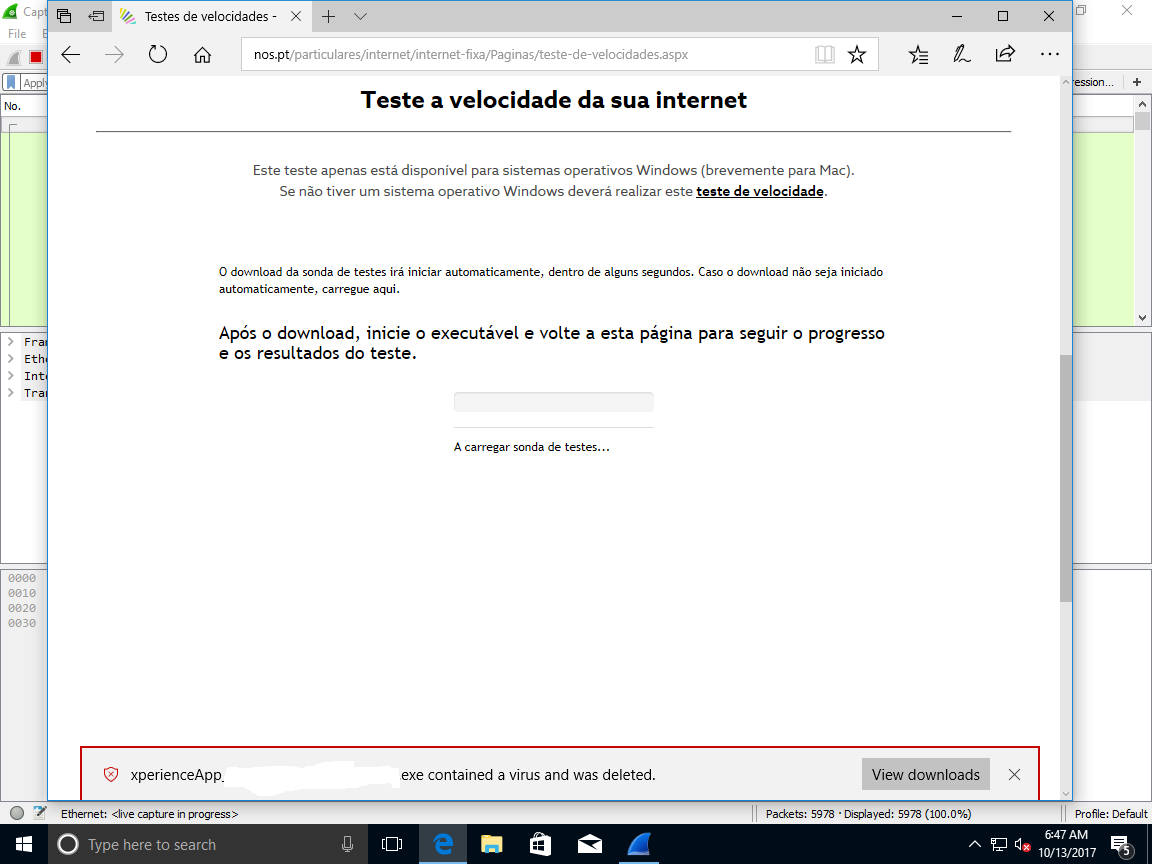
Pelos vistos analisar o executável no virustotal foi o que chegou para ficar blacklisted no Windoze Defender. Que LOLocausto. Então siga desactivar o Windoze Defender para poder correr isto numa VM para poder ligar para la a reclamar que tenho a net lixada...
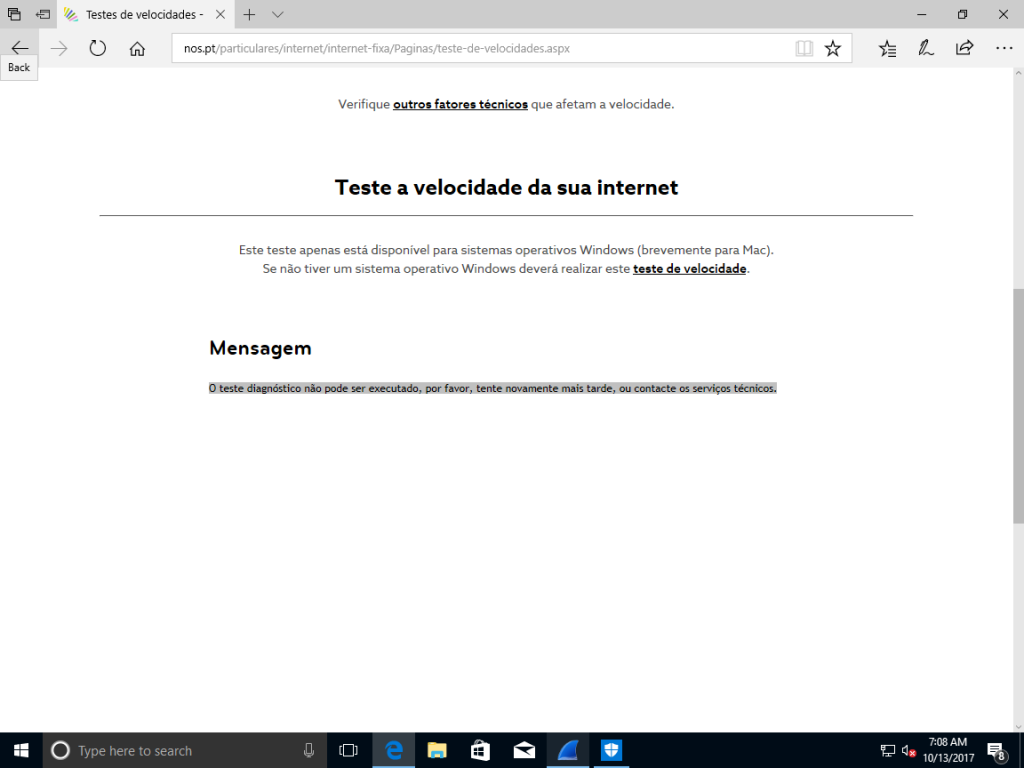
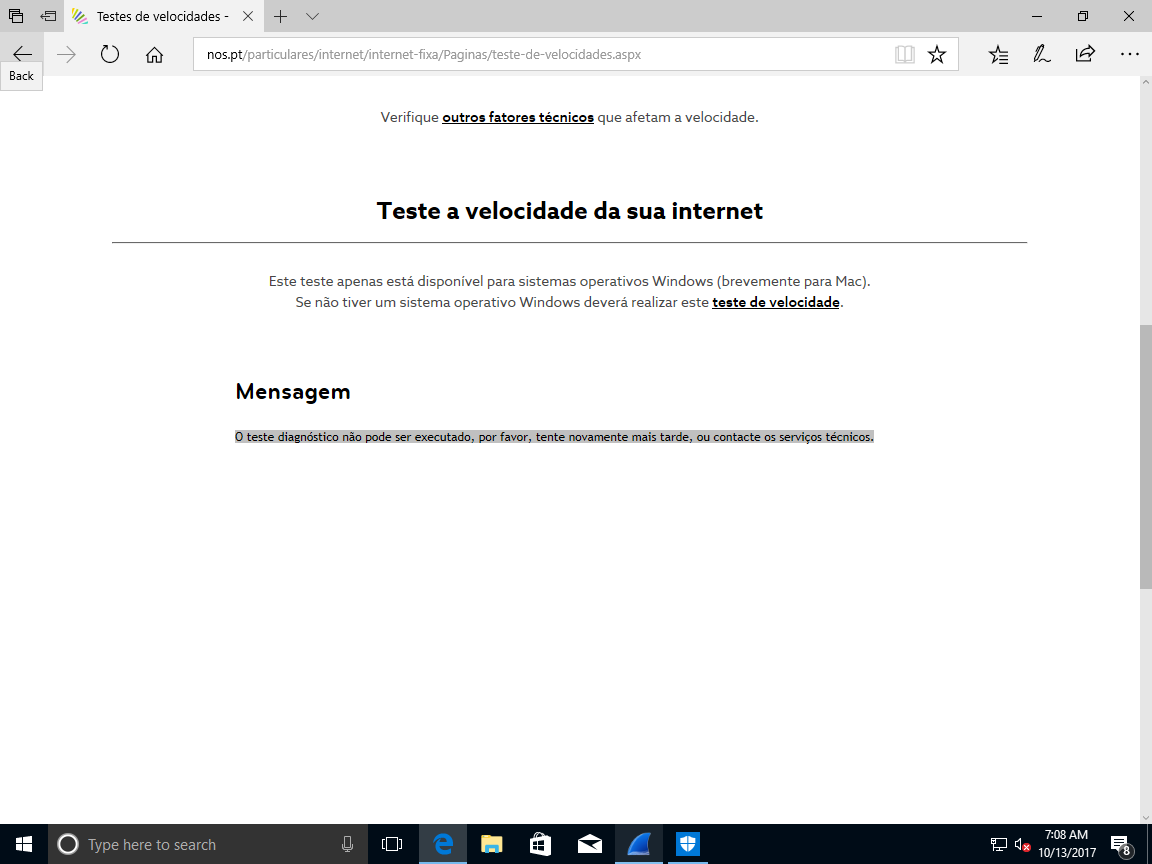
Após estar ali um tempo a engonhar, a app saiu, o browser ficou à espera, e acabou por dar esse erro.
O pessoal que só usa Linux ou OSX deve também estar fascinado com esta mudança, não consigo entender como em 2017, onde existem mil ferramentas em JS pro browser, fds... o speedtest.net usa js e html5 e funciona bem, não entendo como pareceu bem na cabeça de alguém obrigar as pessoas a sacar um executável para correr.
Entendo que queiram sacar essas informações ao utilizador NORMIE para ajudar a diagnosticar problemas que possam não estar relacionados com o serviço deles, mas ao menos separavam isso numa ferramenta diferente, não punham isso no speedtest.
E também convinha fazerem isto de uma forma menos SHADY porque esconder executáveis dentro de outro executável é logo meio caminho andado para bater com os dentes no anti vírus.
Sinceramente agora nem sei o que fazer, porque nem consigo correr o speedtest para reclamar do serviço, portanto decidi vir blogar sobre isso.
Edit: Pelos vistos eles já adicionaram o tester antigo novamente ao site, portanto já não devo pelo menos ser obrigado a correr isto :-)
Edit2: Já rolaram cabeças em algum lado, e o teste já não está online, já voltou o antigo a ser o default.